大数据补充
大数据三种计算模式
- 离线计算,小时级,批处理,机器学习,MapReduce,Spark
- 在线计算,分钟级和秒级,交互分析和查询,Hive,Impala,Spark
- 流计算,秒、毫秒级,实时分析,Storm,Flume,Spark
大数据分层结构
数据收集层:数据抽取、转换、加载(Extract,Transform,Load,ETL),代表技术平台或产品:Kettle,Kafka,Flume(日志收集),Sqoop
数据存储层:分布式文件系统GFS/HDFS,半结构化/结构化数据分布式存储BigTable/HBase,NoSQL(键值、列、图、文档),NewSQL(关系数据库+云计算)
数据分析层:分布式计算框架MapReduce,Spark,Hive(提供大数据类SQL查询接口),Impala,Storm,Mahout(大数据挖掘)
数据应用层:
云计算特点
服务计算: 按需计算: 弹性计算:扩展、收缩
虚拟化计算:磁盘存储、CPU计算、网络带宽进行集中和虚拟化 透明计算:
云计算分层结构
Iaas层(Infrastructure as a
Service):基础设施即服务,磁盘、CPU、网络带宽进行虚拟化,以服务形式提供
PaaS层(Platform as a
Service):平台即服务,操作系统、存储、计算中间件服务 SaaS层(Software
as a Service):软件即服务,应用程序作为服务
云计算类型
公有云 私有云 混合云
Hadoop
Apache 开源分布式存储与计算平台/框架
包括分布式存储HDFS,分布式计算Hadoop
MapReduce,CPU、内存等资源管理Yarn等三大组件
主从架构:一主多从,主节点进行数据和计算任务的管理,从节点进行具体数据的存储和任务的计算
Java语言
一般是要安装在Linux操作系统(Ubuntu,CentOS),64位操作系统;
实验一般要搭建一个小型的集群,即1台主机(主节点,master,名称节点name
node)2台从机(从节点,slave,数据节点data node),e.g.
4G内存,主机2G内存,从机1G内存 事实上的大数据标准
Google(老)三大技术(三驾马车)
GFS:Google File System,Google分布式文件存储系统
MapReduce:Google分布式计算框架
BigTable:Google半结构/结构化数据分布式存储
Hadoop特点
高扩展性:横向扩展(增加单机数量),传统的小型机等纵向扩展(增强单机性能)
高容错性:三副本机制,热点数据请求卸载(offload)
传统并行分布式计算技术MPI(消息传递机制)
高易用性:提供了分布式存储和计算框架,将通用的分布式存储和计算任务(e.g.
不同节点的通讯、任务或数据的划分、任务或数据的容错处理)进行实现,
用户主要实现Map和Reduce函数
Linux常用操作命令
Linux常用操作命令
(以Ubuntu为例,打开终端快捷键:ctrl+alt+t,如果设置的话)
文件(夹)操作命令: ls:显示文件夹/目录内容,ll显示详细的内容信息
cd:切换文件夹/目录 mkdir:创建文件夹/目录 cp:拷贝文件(夹)
(参数:srcdir desdir) mv:移动文件(夹) rm:删除文件(夹)
cat:查看文件内容 pwd:显示当前目录路径 vi/vim:Linux的命令方式的记事本
gedit:Linux的窗口界面的记事本
. 当前目录 .. 上级目录 ~ 用户主目录 / 根目录
权限管理命令
chown:修改文件(夹)权限,文件(夹)权限:可读、可写、可执行
sudo:临时提升到更高权限,例管理员或超级用户 su:切换用户
ssh:远程访问命令,提供安全访问机制(公钥、私钥);在Hadoop中用于保障安全下无需输入密码来远程启动集群节点的计算进程、数据访问
用户创建命令
useradd:增加Linux操作系统用户 passwd:修改密码
apt-get install:安装包
sudo tar -zxf:压缩包解压
hostname:查看机器名称 ifconfig:查看机器ip gedit
/etc/hosts:修改机器名称与ip映射 (vi
/etc/hosts:修改机器名称与ip映射)
ping:ping对方机器
exit:退出
ssh-keygen:生成公钥和私钥
Hadoop操作接口
- 终端命令接口
- Web界面
Hadoop解压后的主要配置文件: core-site.xml hdfs-site.xml
mapred-site.xml
Hadoop命令: hadoop namenode -format:HDFS 分布式文件系统格式化
start-all.sh:Hadoop 启动所有进程 jps:显示所有Java进程,包括: Hadoop
master的必要进程:NameNode,ResourceManager,SecondaryNameNode Hadoop
slave的必要进程:DataNode,NodeManager
stop-all.sh:Hadoop 关闭所有进程
hadoop dfs:HDFS操作命令 e.g. hadoop dfs -ls / hadoop dfs -mkdir
hadoop dfs -cat hadoop dfs -put:将本地文件上传到HDFS分布式文件系统中
hadoop dfs -get:将HDFS分布式文件系统中文件下载到本地
HDFS系统结构
一主多从
HDFS主节点,又称名称节点,NameNode,进行数据的划分以及位置等元数据(metadata,保存了文件、数据块和数据节点的映射关系)管理,并转发数据访问请求;
HDFS从节点,又称数据节点,DataNode,进行具体数据的存储和访问;
(HDFS第二主节点,又称HDFS第二名称节点)
HDFS特点
流数据读写:适合顺序读写,而不是随机读写
大容量数据读写:高吞吐量数据读写,而不是多个小文件读写
HDFS默认数据块大小64MB,默认的数据块副本3个
HDFS操作接口
- 终端命令接口
- Web界面:http://master:50070
- 编程接口API
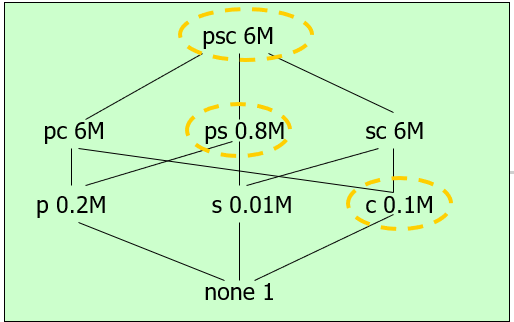
例子:假设有2个文件,共5个数据块,其id分别为1,2,3,4,5,2副本机制,分布式存储到3个数据节点,请设计相应的分布式存储方案。
(满足1. 每个数据块2副本;2. 每个数据节点的数据块个数(几乎)相等 )
设计方案之一: 1:1,4,2,5 2:2,5,3 3:3,1,4
Hadoop安装部署
(系统配置一般需要root用户权限,其它一般是hadoop用户,如zkpk用户)
- 安装或载入(Ubuntu)虚拟机,如果该虚拟机没有Hadoop打包文件,则需要下载并解压
- 修改节点名称为好记的名称(hostname),e.g. master, slave,
slave2
- 配置/etc/hosts(gedit、vim进行编辑),可以ping从节点机器名称
- 在主节点生成公钥和私钥(ssh-keygen,ssh-copy-id),将公钥拷贝到其它从节点机器,可以无密码ssh远程访问其它从节点机器
- 配置/hadoop-2.5.2/etc/hadoop/slaves(gedit、vim进行编辑)
- 如果需要,配置core-site.xml、hdfs-site.xml、mapred-site.xml(/hadoop-2.5.2/etc/hadoop路径下)
- 在主节点启动Hadoop所有进程 start-all.sh
- jps查看进程,master有4个进程,slave有3个进程
- 进行HDFS分布式文件系统命令操作,e.g. hadoop dfs -ls / , hadoop dfs
-ls mkdir input-20211114, hadoop dfs -put
- 进行MapReduce示例程序运行,hadoop jar wordcount.jar WordCount input
output e.g. hadoop jar wordcount.jar org/zkpk/day0909/WordCount
/input-20211114 /output-20211114
以上步骤2、3、5、6要在每台虚拟机都需要操作。
MapReduce
MapReduce与传统并行编程框架的区别
MapReduce可扩展性好,容错性好、廉价、编程容易(数据划分、任务分发、数据通讯、负载均衡等通用任务自动处理)、数据密集型计算(不是计算密集型应用)、移动计算而不是移动数据
MapReduce体系结构
Client:客户端,提交分布式应用程序给主节点(的JobTracker);
JobTracker+Task
Scheduler:在主节点运行的作业跟踪和调度(一个Job有多个Task,一个Task可以是Map计算任务或者Reduce计算任务)
TaskTracker:在从节点运行的具体任务执行(通过CPU、内存资源槽(slot)来分配Map或Reduce计算任务)
MapReduce工作流程
主要分为四个阶段 (数据先上传到HDFS) 1)Split:对数据进行分片 ->
(key, value);
2)Map:每个数据分片上启动一个Map计算任务,计算该数据分片的数据;
(key, value) -> list(out_key, intermediate_value)
3)Shuffle:对数据进行混排,类似group by; (out_key,
intermediate_value) -> (out_key, list(intermediate_value))
(Combine:对相同out_key的值提前进行合并,即提前进行本地的Reduce,从而有效减少Shuffle的输出)
4)Reduce:对混排后的数据进行聚集、约减 (out_key,
list(intermediate_value)) -> (out_key, out_value) (其中out_value =
Agg(list(intermediate_value)) (最终结果HDFS文件系统)
MapReduce编程示例
输入: Hello World Bye World Hello Hadoop Bye Hadoop Bye Hadoop Hello
Hadoop
输出: <Bye, 3> <Hello, 3> <World, 2> <Hadoop,
4>
Map输入: [Hello World Bye World] [Hello Hadoop Bye Hadoop] [Bye
Hadoop Hello Hadoop]
Map输出: <Hello, 1> <World,1> <Bye, 1> <World,
1>
<Hello, 1> <Hadoop, 1> <Bye, 1> <Hadoop,
1>
<Bye, 1> <Hadoop,1> <Hello, 1> <Hadoop,
1>
Shuffle输入(=Map输出): <Hello, 1> <World,1> <Bye,
1> <World, 1>
<Hello, 1> <Hadoop, 1> <Bye, 1> <Hadoop,
1>
<Bye, 1> <Hadoop,1> <Hello, 1> <Hadoop,
1>
Shuffle输出: <Bye, <1, 1, 1>> <Hello,
<1,1,1>> <World, <1,1>> <Hadoop,
<1,1,1,1>>
Reduce输入(=Shuffle输出): <Bye, <1, 1, 1>> <Hello,
<1,1,1>> <World, <1,1>> <Hadoop,
<1,1,1,1>>
Reduce输出: <Bye, 3> <Hello, 3> <World, 2>
<Hadoop, 4>